Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

What to Learn About Spark Performance Tuning? : r/dataengineering

Azarudeen S on LinkedIn: #spark #apachespark #spark #optimization #interviewpreparation

Kiran Sreekumar on LinkedIn: #databricks #spark #performanceoptimization
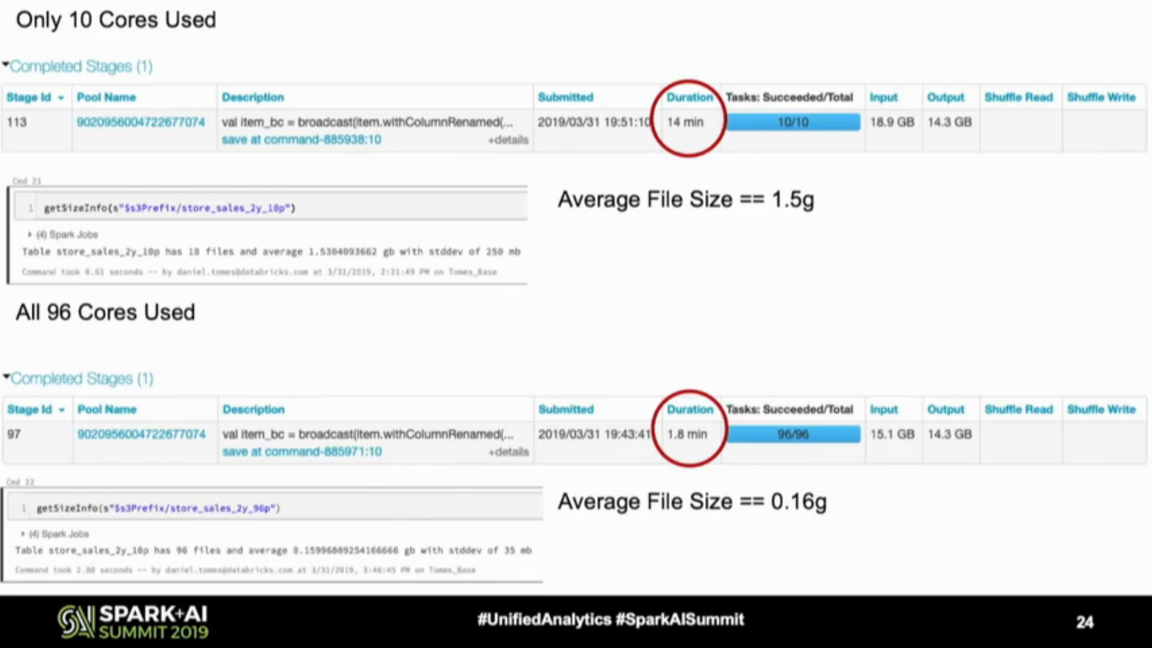
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark

Spark Performance Optimizations Deep-Dive, Become Pro, LinkedIn Live

Apache Kafka With Spark Structured Streaming With Emma Liu, Nitin Saksena, Ram Dhakne, Current 2022
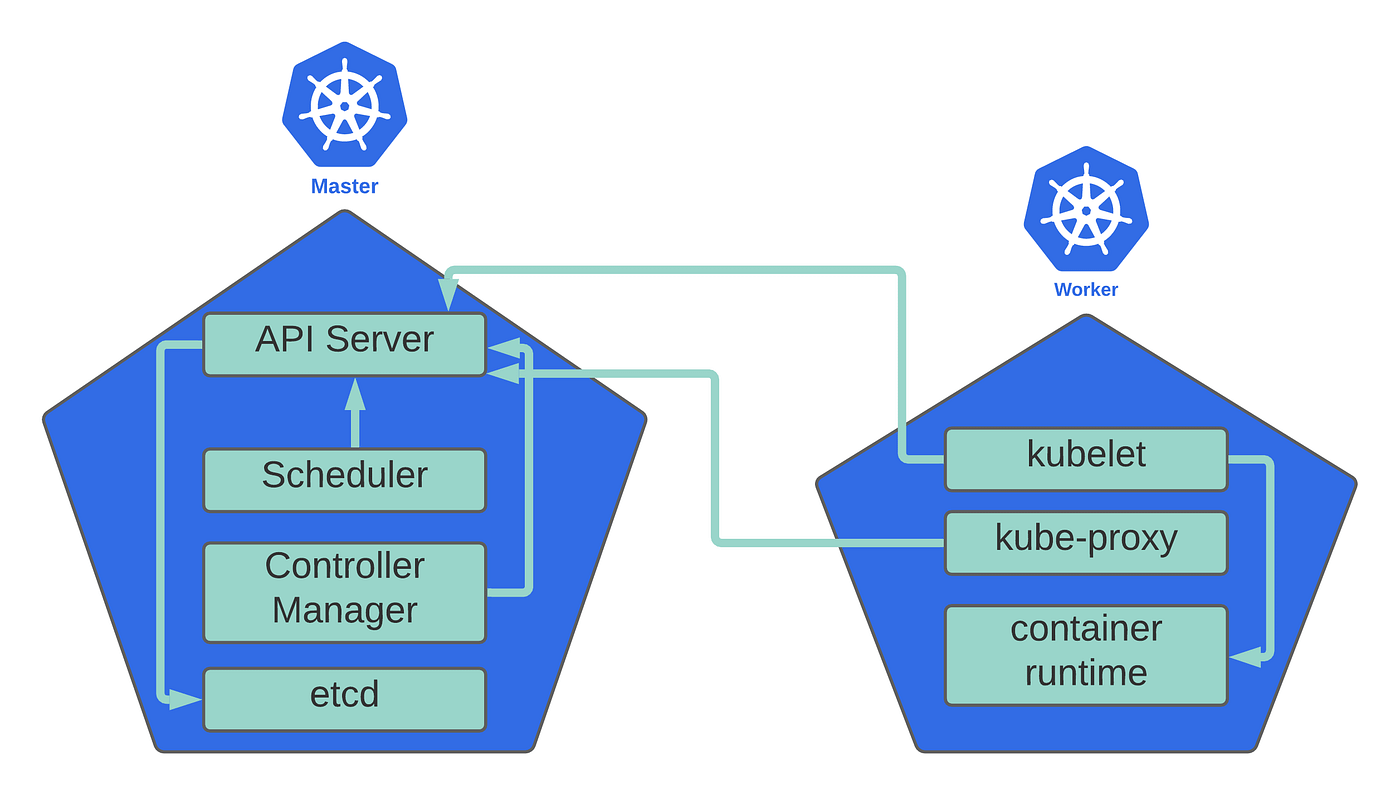
Kubernetes Architecture,Hands On!, by Himansu Sekhar
High Performance Spark [Book]
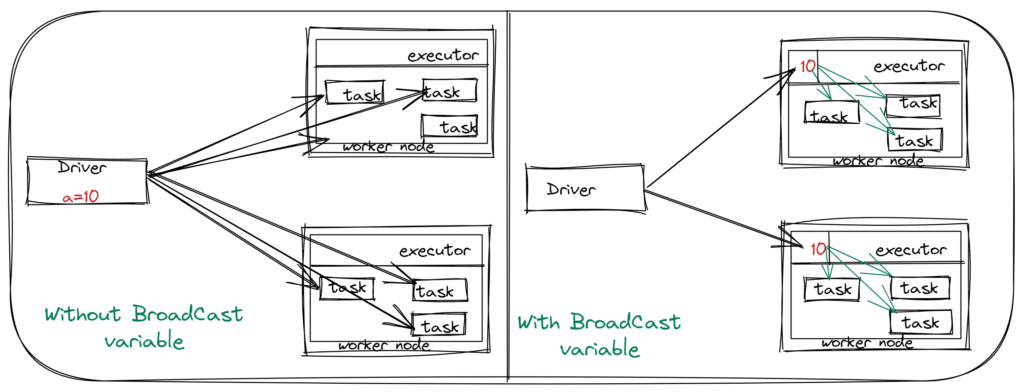
Best Practices and Spark optimization Tips for Data engineers - StatusNeo

Data engineering and intelligent computing : proceedings of IC3T 2016 978-981-10-3223-3, 9811032238, 978-981-10-3222-6

Kiran Sreekumar on LinkedIn: #databricks #spark #performanceoptimization

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

miro./v2/resize:fit:1400/1*KZ5rcmwhysMBj
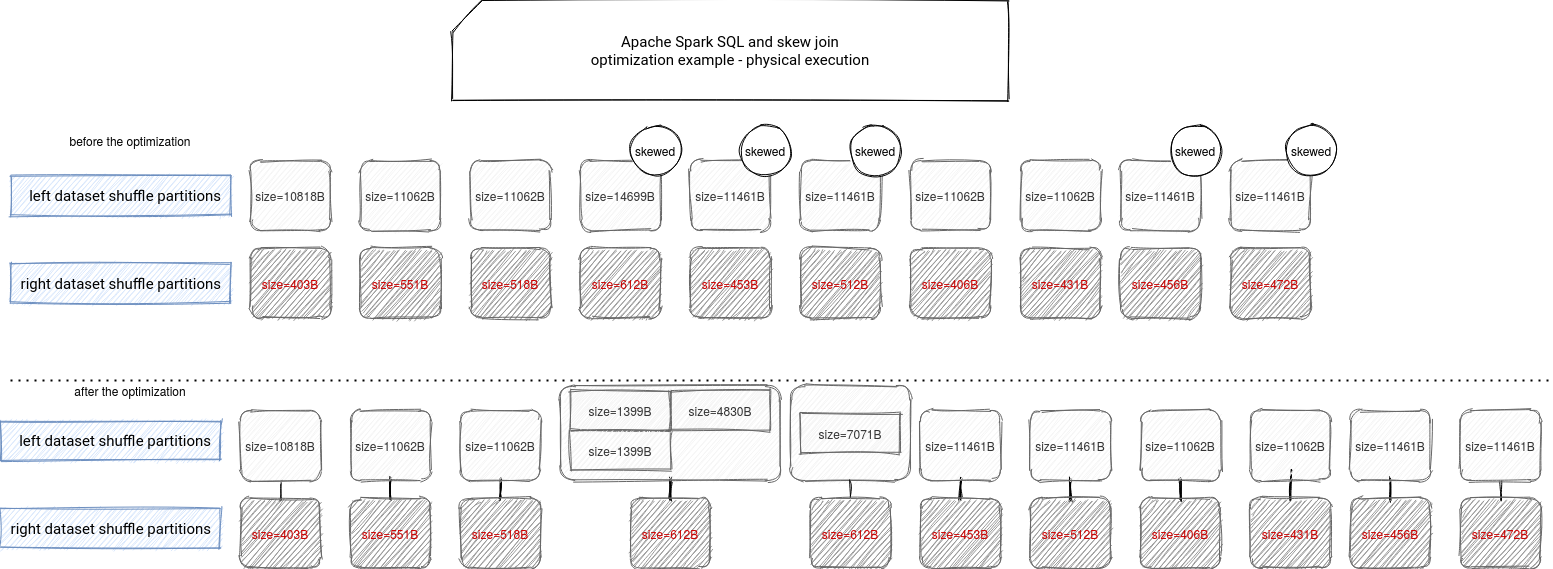
What's new in Apache Spark 3.0 - join skew optimization on - articles about Apache Spark SQL