Language models might be able to self-correct biases—if you ask them

A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Articles by Niall Firth

Articles by Tammy Xu MIT Technology Review

The 5 Biggest Biases That Affect Decision-Making

Anthropic - Research Scientist, Societal Impacts

Articles by Will Douglas Heaven

Research Scientist, Societal Impacts at Anthropic - The Rundown Jobs

language-models/llm-23.md at master · gopala-kr/language-models
My interview with Assistant, a large language model based on ChatGPT-3, developed by OpenAI.

Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy - ScienceDirect
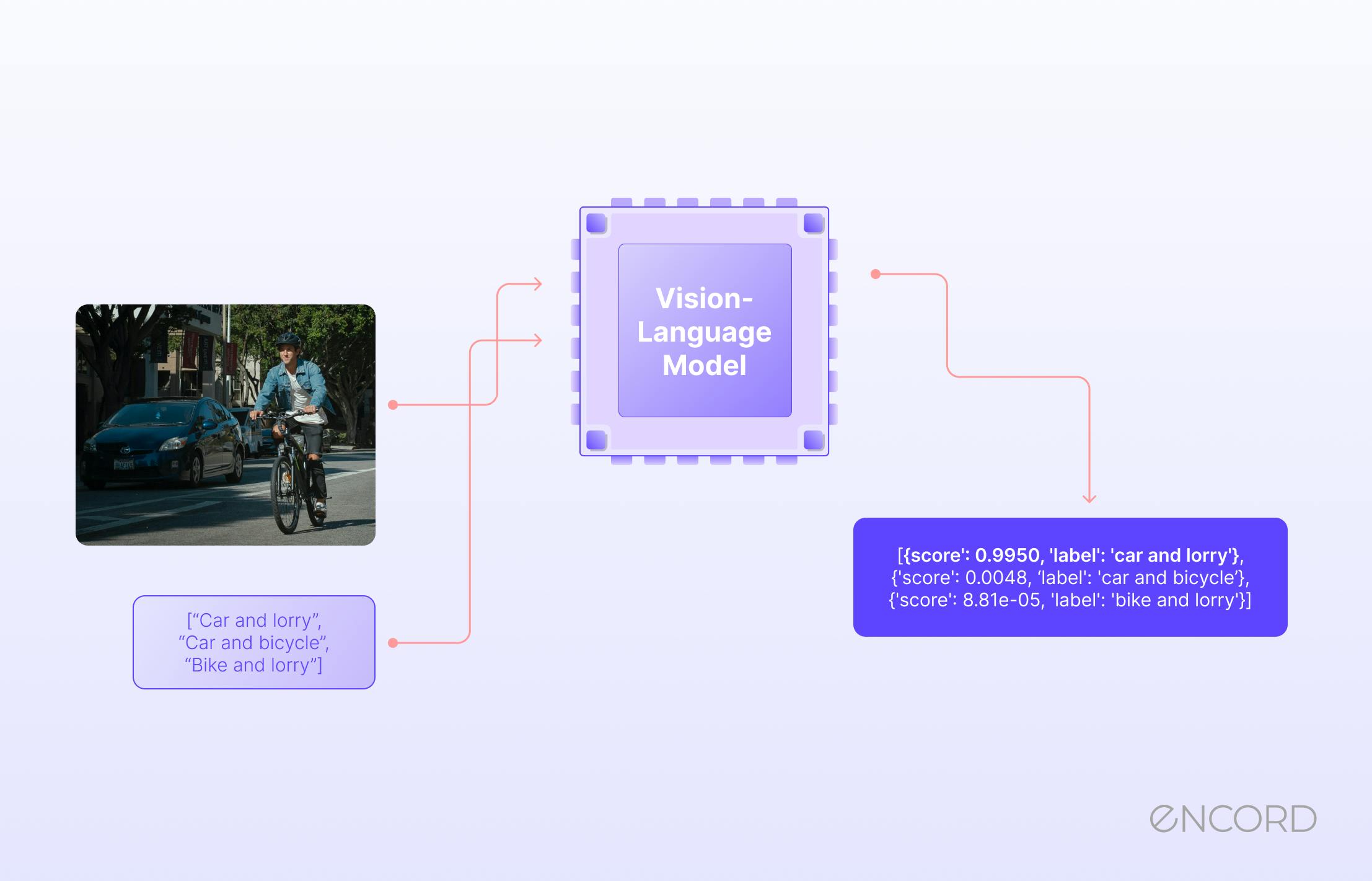
Unlocking the Power of Vision-Language Models: Understanding Their Mechanisms and Overcoming Challenge

Simon Porter on LinkedIn: Language models might be able to self