Reinforcement Learning as a fine-tuning paradigm

Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

Active Learning in Machine Learning [Guide & Examples]
.png)
Non-Generalization and Generalization of Machine learning Models
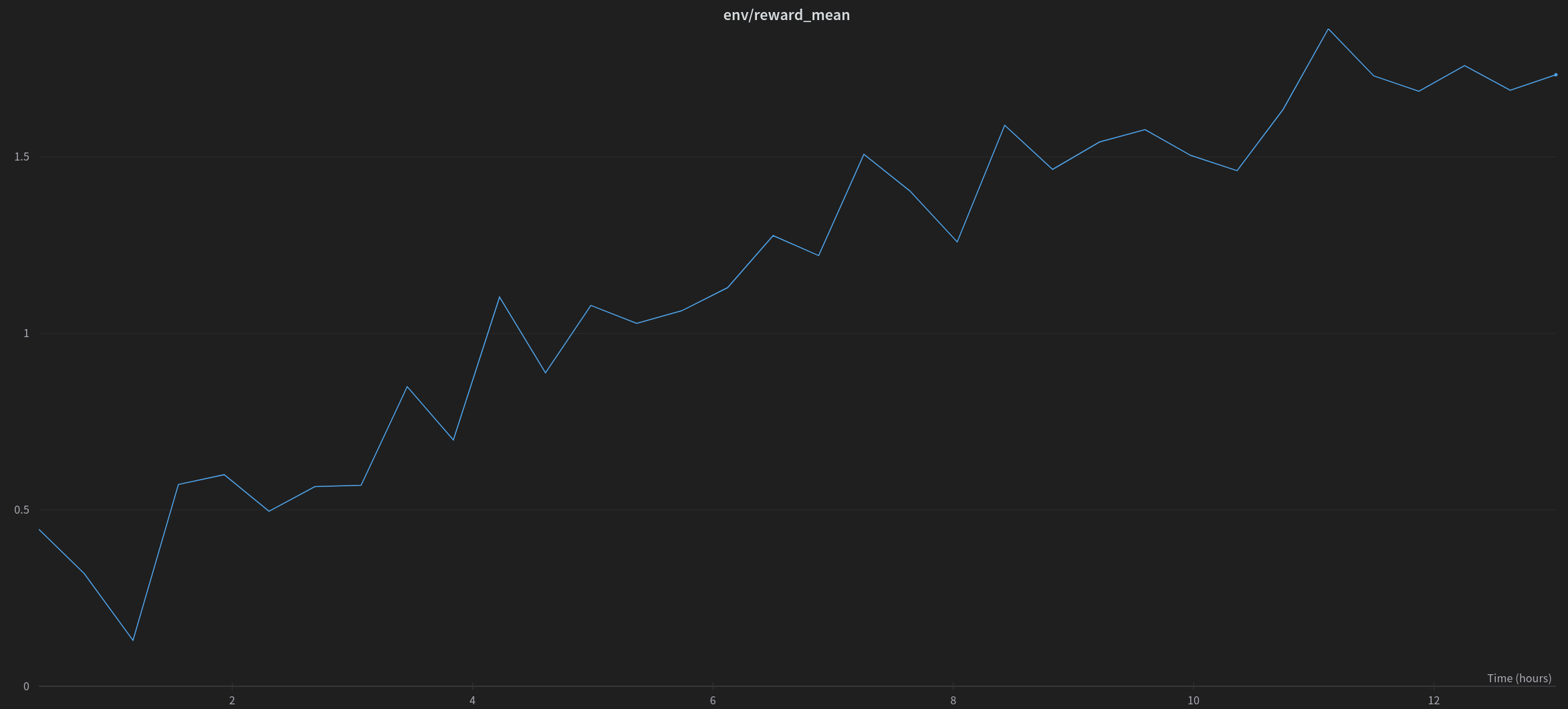
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

Machine Learning Paradigms, Algorithms, and Their Applications
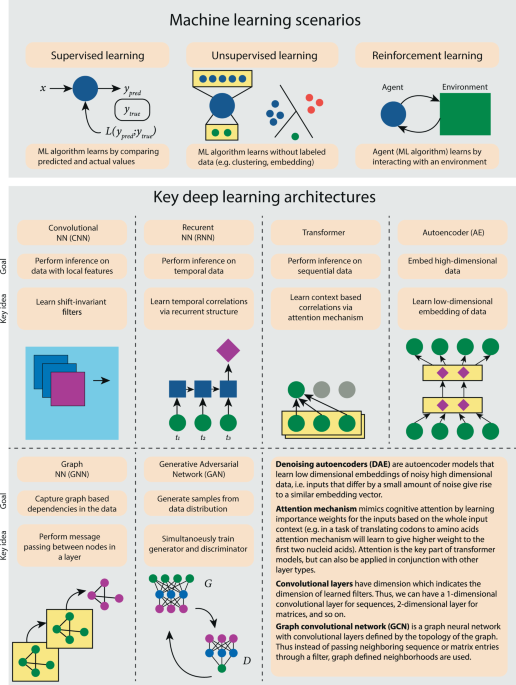
Current progress and open challenges for applying deep learning

Fine tunning Large Language Language Models (LLMs) in 2024
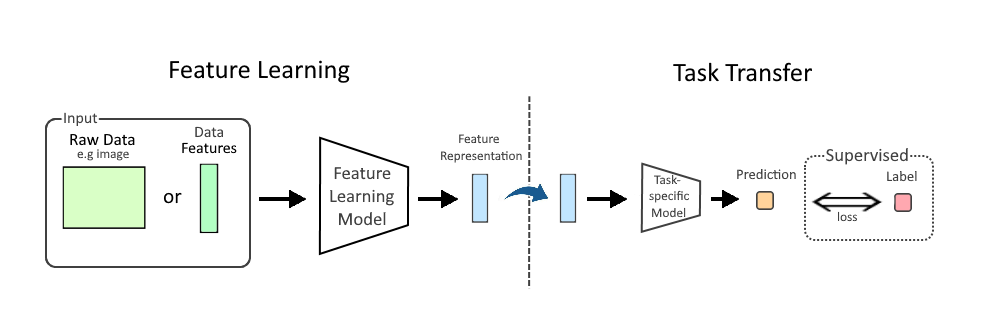
Feature learning - Wikipedia
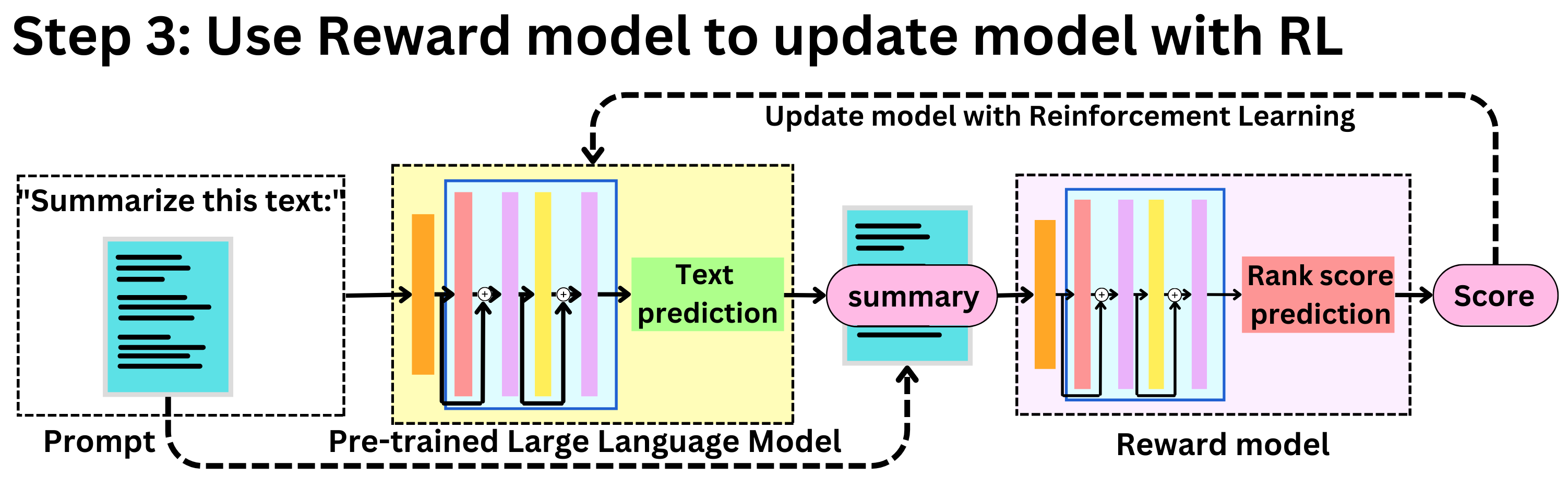
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

arxiv-sanity

Reinforcement Learning Pretraining for Reinforcement Learning Finetuning
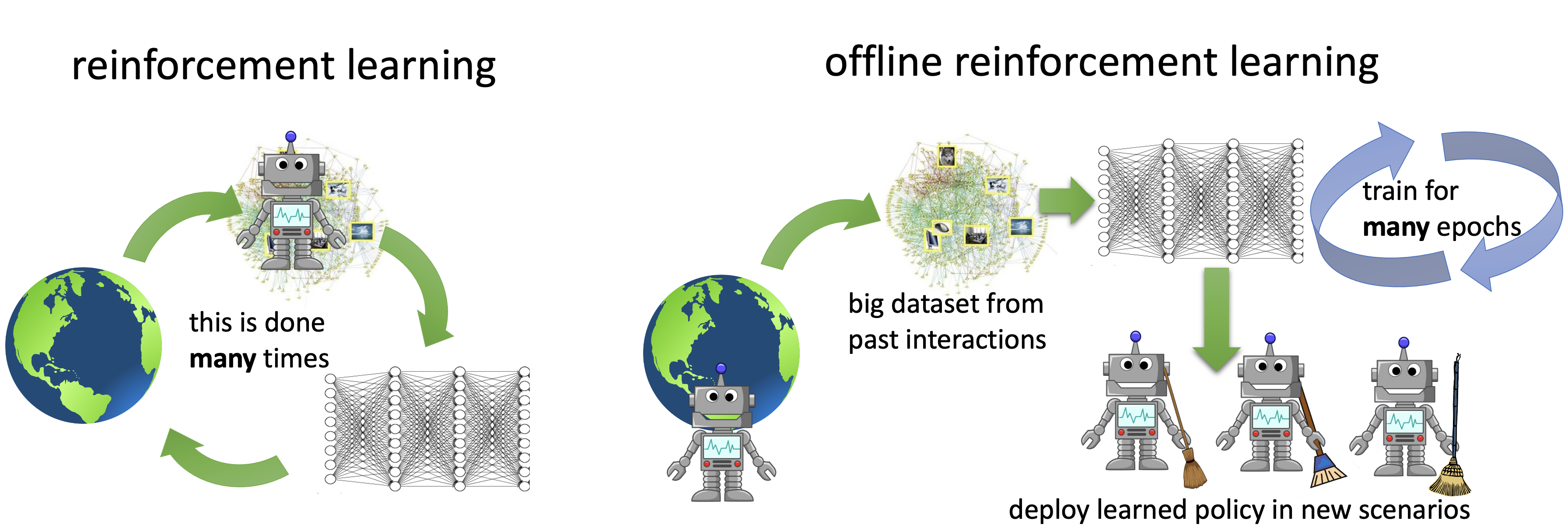
Offline Reinforcement Learning: How Conservative Algorithms Can

Mina Khan (@minakhan01) / X
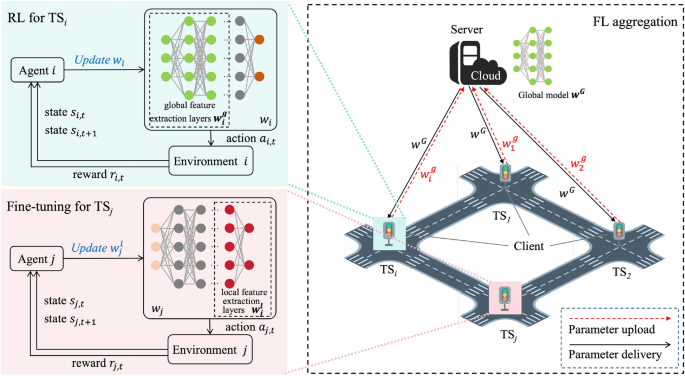
A scalable approach to optimize traffic signal control with
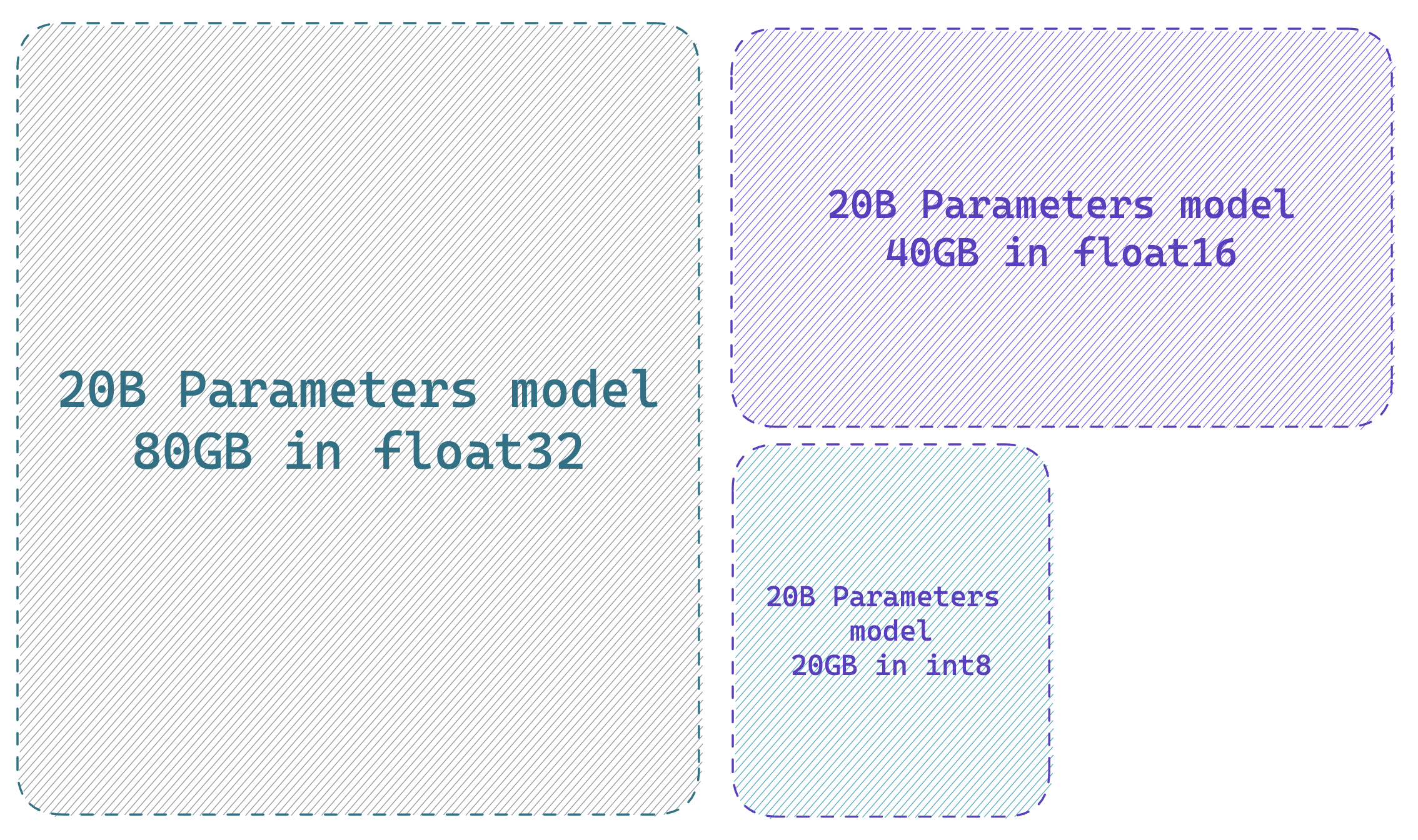
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU