We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

PDF) How to Fine-Tune Vision Models with SGD

PDF) Vision Models Can Be Efficiently Specialized via Few-Shot Task-Aware Compression
Frontiers High-throughput UAV-based rice panicle detection and genetic mapping of heading-date-related traits
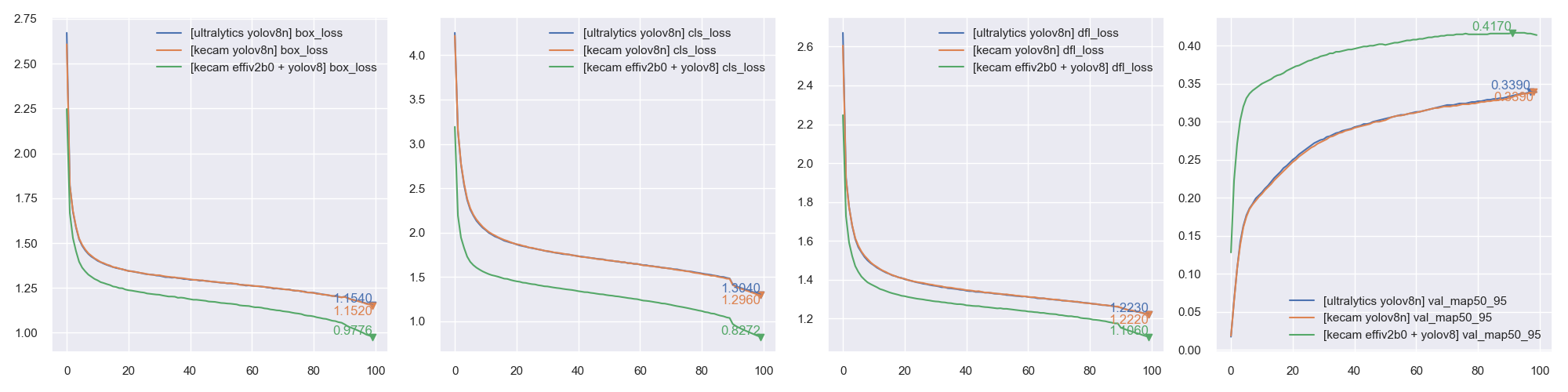
GitHub - leondgarse/keras_cv_attention_models: Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet
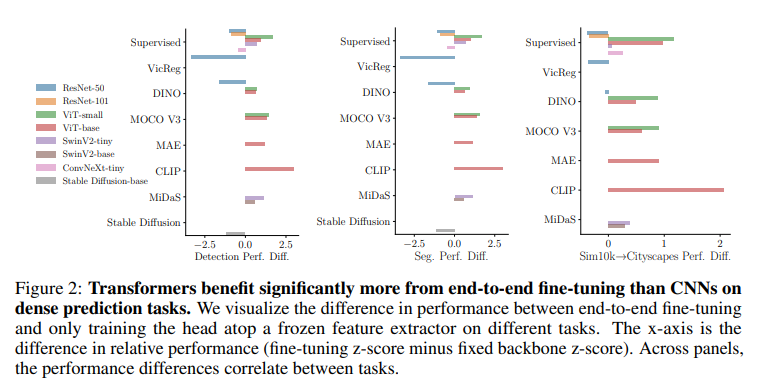
The Computer Vision's Battleground: Choose Your Champion

Review — ConvNeXt: A ConvNet for the 2020s, by Sik-Ho Tsang
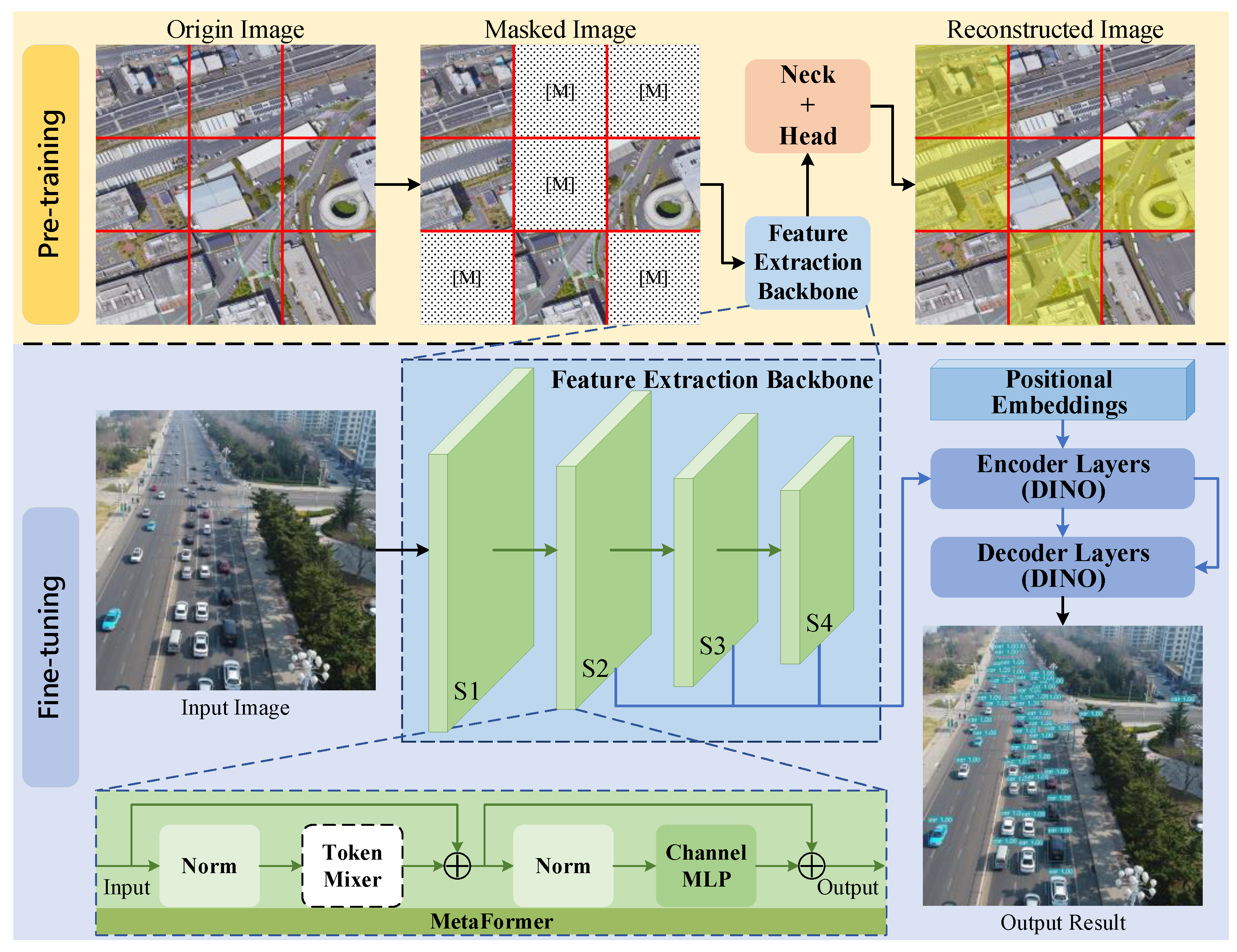
Remote Sensing, Free Full-Text
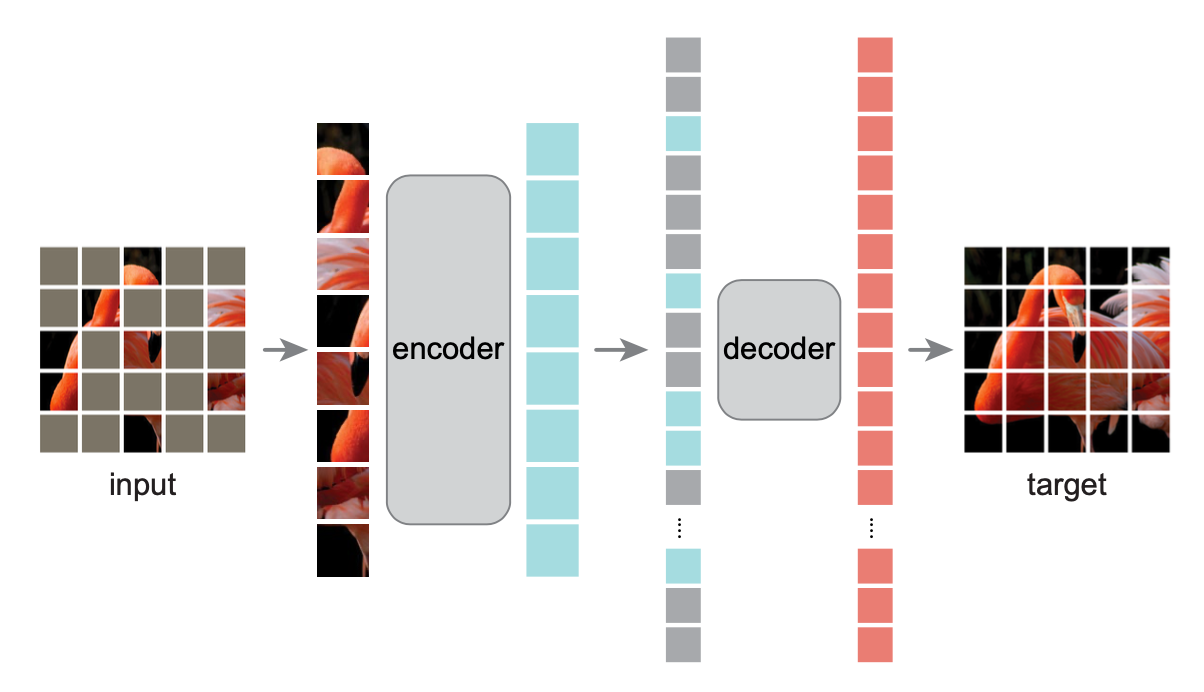
Masked Autoencoders Are Scalable Vision Learners, by Ahmed Taha

Frontiers High-throughput UAV-based rice panicle detection and genetic mapping of heading-date-related traits

GitHub - huggingface/pytorch-image-models: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT), MobileNet-V3/V2, RegNet, DPN, CSPNet, Swin Transformer, MaxViT, CoAtNet, ConvNeXt, and more

Vision Transformer (ViT)

R] [ICLR'2023 Spotlight🌟]: The first BERT-style pretraining on CNNs! : r/MachineLearning

Review — ConvNeXt: A ConvNet for the 2020s, by Sik-Ho Tsang