DistributedDataParallel non-floating point dtype parameter with
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
Error using DDP for parameters that do not need to update gradients · Issue #45326 · pytorch/pytorch · GitHub

PyTorch Numeric Suite Tutorial — PyTorch Tutorials 2.2.1+cu121 documentation
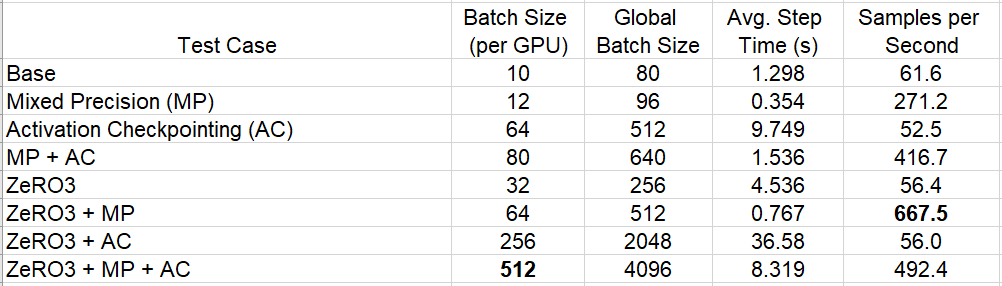
How to Increase Training Performance Through Memory Optimization, by Chaim Rand

Does moxing.tensorflow Contain the Entire TensorFlow? How Do I Perform Local Fine Tune on the Generated Checkpoint?_ModelArts_Troubleshooting_MoXing

Pytorch Lightning Manual Readthedocs Io English May2020, PDF, Computing
fairscale/fairscale/nn/data_parallel/sharded_ddp.py at main · facebookresearch/fairscale · GitHub
apex/apex/parallel/distributed.py at master · NVIDIA/apex · GitHub

PYTORCH💫IN-DEPTH COURSE 2023 - for Indian Kaggler

Configure Blocks with Fixed-Point Output - MATLAB & Simulink - MathWorks Nordic

Multi-Node Multi-Card Training Using DistributedDataParallel_ModelArts_Model Development_Distributed Training
change bucket_cap_mb in DistributedDataParallel and md5 of grad change · Issue #30509 · pytorch/pytorch · GitHub
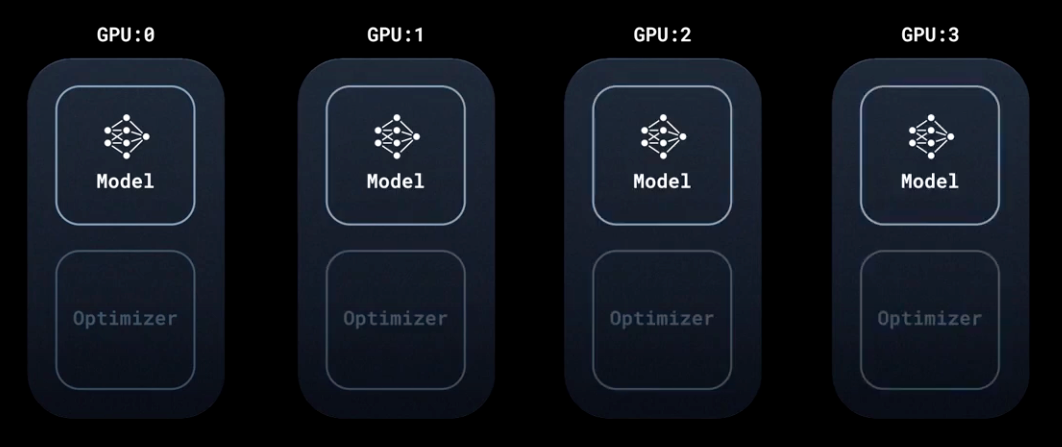
A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher